Find out all tables without indexes in Sql Server
Hey folks till now we have discussed Performance improvement of cursor SQL Server, User defined functions in sql, Kill Processes in sql server 2008, View in sql , default constraint in sql , Remove Cross duplicate rows in SQL, Recursive SQL Query , Recursive SQL Query-2, STUFF and CONCAT in SQL, RANK in SQL server , Difference between temporary table and table variable in sql server, UNIQUEIDENTIFIER in SQL Server, RAW Mode with FOR XML , AUTO Mode with FOR XML, EXPLICIT Mode with FOR XML , PATH Mode with FOR XML, OUTPUT Clause in SQL Server, Difference between delete and truncate in sql server etc.
Today we will find out all tables without indexes for particular database in Sql Server.
We all have different myths regarding whether there should be indexes on table or not, but today we will first find out which tables contains how many indexes and then find out all tables which are without indexes in Sql Server.
Tables contains how many indexes
WITH cte AS
(
SELECT
table_name = obj.name,
obj.[object_id],
ind.index_id,
ind.type,
ind.type_desc
FROM sys.indexes ind
INNER JOIN sys.objects obj on ind.[object_id] = obj.[object_id]
WHERE obj.type in ('U')
AND obj.is_ms_shipped = 0 and ind.is_disabled = 0 and ind.is_hypothetical = 0
AND ind.type <= 2
), cte2 AS
(
SELECT * FROM cte c
PIVOT (count(type) for type_desc in ([HEAP], [CLUSTERED], [NONCLUSTERED])) pv
)
SELECT
c2.table_name AS 'Table Name',
[ROWS] = max(p.rows),
IS_HEAP = sum([HEAP]),
IS_CLUSTERED = sum([CLUSTERED]),
NUM_OF_NONCLUSTERED = sum([NONCLUSTERED])
FROM cte2 c2
INNER JOIN sys.partitions p
ON c2.[object_id] = p.[object_id] AND c2.index_id = p.index_id
GROUP BY table_name
Sample Output:
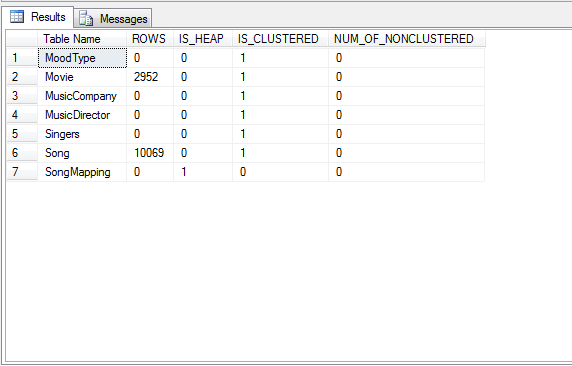
Find out on which tables don’t have any Clustered and Non Clustered Indexes on tables
WITH cte AS
(
SELECT
table_name = obj.name,
obj.[object_id],
ind.index_id,
ind.type,
ind.type_desc
FROM sys.indexes ind
INNER JOIN sys.objects obj on ind.[object_id] = obj.[object_id]
WHERE obj.type in ('U')
AND obj.is_ms_shipped = 0 and ind.is_disabled = 0 and ind.is_hypothetical = 0
AND ind.type <= 2
), cte2 AS
(
SELECT * FROM cte c
PIVOT (count(type) for type_desc in ([HEAP], [CLUSTERED], [NONCLUSTERED])) pv
)
SELECT
c2.table_name AS 'Table Name',
[ROWS] = max(p.rows),
IS_HEAP = sum([HEAP]),
IS_CLUSTERED = sum([CLUSTERED]),
NUM_OF_NONCLUSTERED = sum([NONCLUSTERED])
FROM cte2 c2
INNER JOIN sys.partitions p
ON c2.[object_id] = p.[object_id] AND c2.index_id = p.index_id
GROUP BY table_name
HAVING SUM([CLUSTERED])>0 AND SUM([NONCLUSTERED])>0
We have just added HAVING clause at the end as you can notice.
Let me know if you have any query.